## Step 4 - Saving data with `DataCatalog`
Reimplementing something is one of the best way to learn. Kedro is a data science & data engineer pipeline library at heart. Under the hood, there are few core components such as ConfigLoader, DataCatalog. You may not notice these classes because the framework allows you to use them implicitly without the need to understand how it actually works.
In this blog post, I am going to re-implement Kedro in 50 lines of code. I will start with the classic spaceflights tutorial, By the end of the blog post, you will have an overview of how Kedro works internally.
Installation
First, clone this repository and install the module and its dependencies in editable mode - git clone https://github.com/noklam/miniKedro.git - pip install -e .
The repository is a simplified version of spaceflights, confirm that you can actually run the pipeline with this command: kedro run
Running the pipeline as a script
The goal of this tutorial is replicate the feature of Kedro by slowly introduce new components. We will start with a pure Python script run.py that doesn’t have any Kedro dependencies.
Execute this script with python run.py
if __name__ == "__main__":
print("Start Pipeline")
from minikedro.pipelines.data_processing.nodes import (
create_model_input_table,
preprocess_companies,
preprocess_shuttles,
)
from rich.logging import RichHandler
import logging
import pandas as pd
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
handlers=[RichHandler()],
)
logger = logging.getLogger("minikedro")
companies = pd.read_csv("data/01_raw/companies.csv")
reviews = pd.read_csv("data/01_raw/reviews.csv")
shuttles = pd.read_excel("data/01_raw/shuttles.xlsx")
logger.info("Running preprocess_companies")
processed_companies = preprocess_companies(companies)
logger.info("Running preprocess_companies")
processed_shuttles = preprocess_shuttles(shuttles)
logger.info("Running create_model_input_table")
model_input_table = create_model_input_table(
processed_shuttles, processed_companies, reviews
)Note that we are still importing from minikedro.pipelines.data_processing.nodes, this is not cheating because it is just a collections of Python function and they can be used outside of Kedro pipeline. Let’s focus on this block of code first:
companies = pd.read_csv("data/01_raw/companies.csv")
reviews = pd.read_csv("data/01_raw/reviews.csv")
shuttles = pd.read_excel("data/01_raw/shuttles.xlsx")
logger.info("Running preprocess_companies")
processed_companies = preprocess_companies(companies)
logger.info("Running preprocess_companies")
processed_shuttles = preprocess_shuttles(shuttles)
logger.info("Running create_model_input_table")
model_input_table = create_model_input_table(
processed_shuttles, processed_companies, reviews
)The code is actually decently structured already, the first 3 lines of code prepare the data, after that there is a few function calls to chain these functions together.
Start of the Journey - Step 1: Extract data configuration
You can find the scripts and corresponding code in https://github.com/noklam/miniKedro/blob/main/run_v1.py. For step two, simply change the v1 to v2
This is the change: 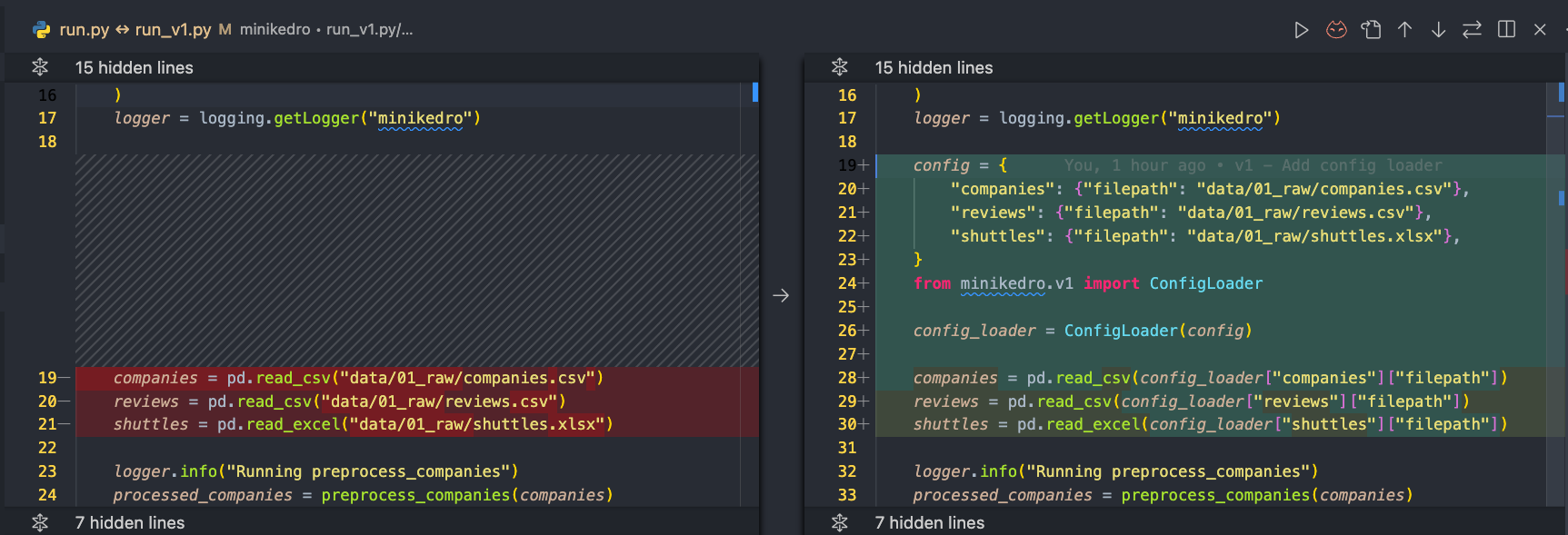
from collections import UserDict
class ConfigLoader(UserDict): ...First, we extract the configuration into a dictionary, and introduce a dictionary-like class called ConfigLoader
Step 2 - Replace shared config with templated value
After extracting the configuration into config, notice that many of the filepath shared a similar pattern. It may make sense to extract that as a variable _base_folder so that it can be easily configure to be something else later (i.e. a s3 bucket).
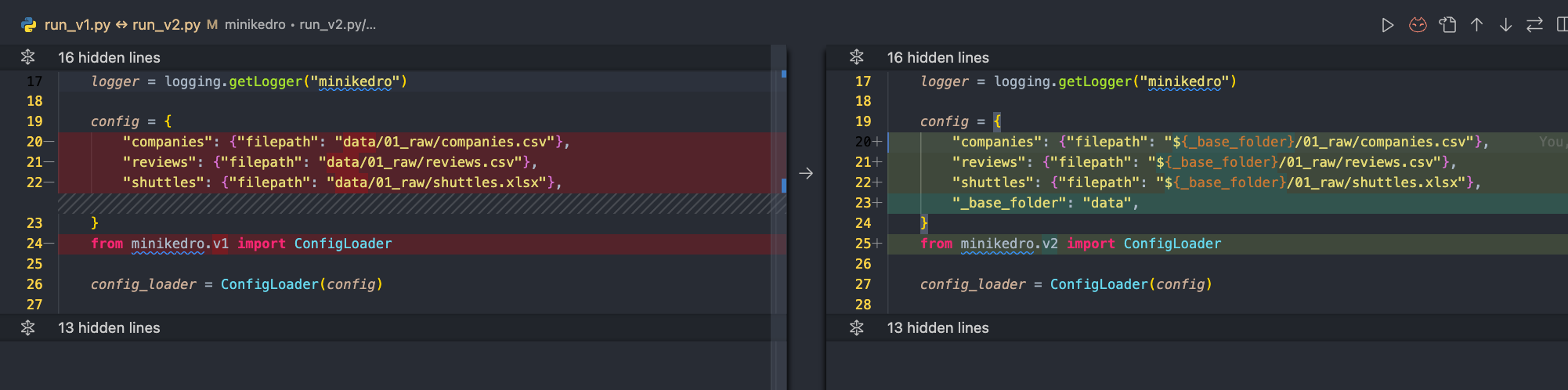
class ConfigLoader(UserDict):
def __init__(self, data: dict):
self.data = OmegaConf.create(data) # NewWe introduce OmegaConf to support template value like ${_base_folder} The idea is simple, all the value of ${_base_folder} will be substituted as data. Kedro also support a lot more advance configuration feature, which you can find in the documentation.
Step 3 - Introducing DataCatalog
The next thing that we will do is to introduce the DataCatalog class. The DataCatalog class and Dataset. A Dataset is something that can save and load, and a DataCatalog is a container of a collections of Dataset(s). Here we leverage the fact that Kedro already has a lot of existing data connectors in kedro-datasets.
class AbstractDataset:
def load(self):
raise NotImplementedError
def save(self, data):
raise NotImplementedError
class DataCatalog:
def __init__(self, config_catalog: dict):
self.datasets = {}
for dataset_name, config in config_catalog.items():
if isinstance(dataset_name, str) and dataset_name.startswith("_"):
continue # skip template value
module = config.pop("type") # pandas.CSVDataset
# CSVDataset(**config) in code
mod, dataset = module.split(".") # pandas, CSVDataset
mod = importlib.import_module(
f"kedro_datasets.{mod}"
) # kedro_datasets.pandas (module)
class_ = getattr(mod, dataset) # kedro_datasets.pandas.CSVDataset
self.datasets[dataset_name] = class_(**config)
def load(self, dataset_name):
return self.datasets[dataset_name].load() # CSVDataset.load()We introduced quite a lot of code here, but most of them are just parsing logic. What’s happening here is that the DataCatalog takes some configurations, and instantiate Dataset class from it.
We can now replaced all the pd call with the DataCatalog instead: 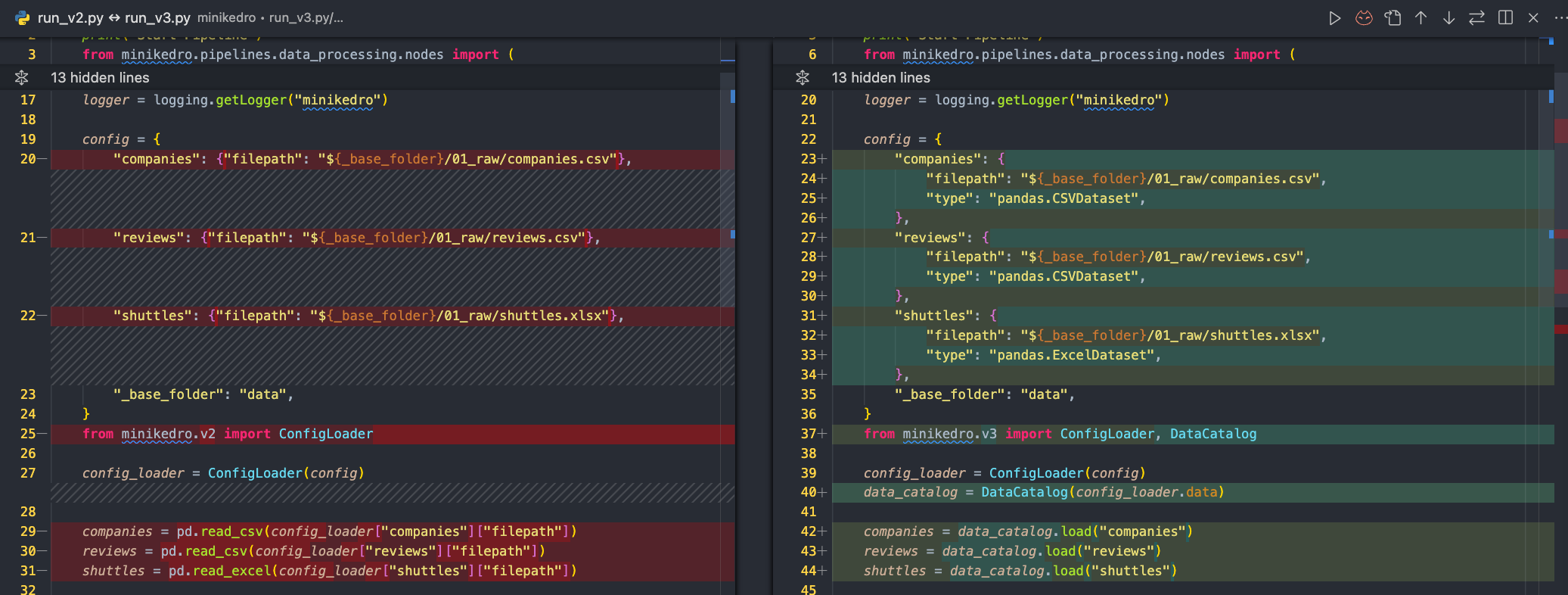
## Step 5 - Extracting configuration again, this time for the functions
Step 6 - Iterating through the steps
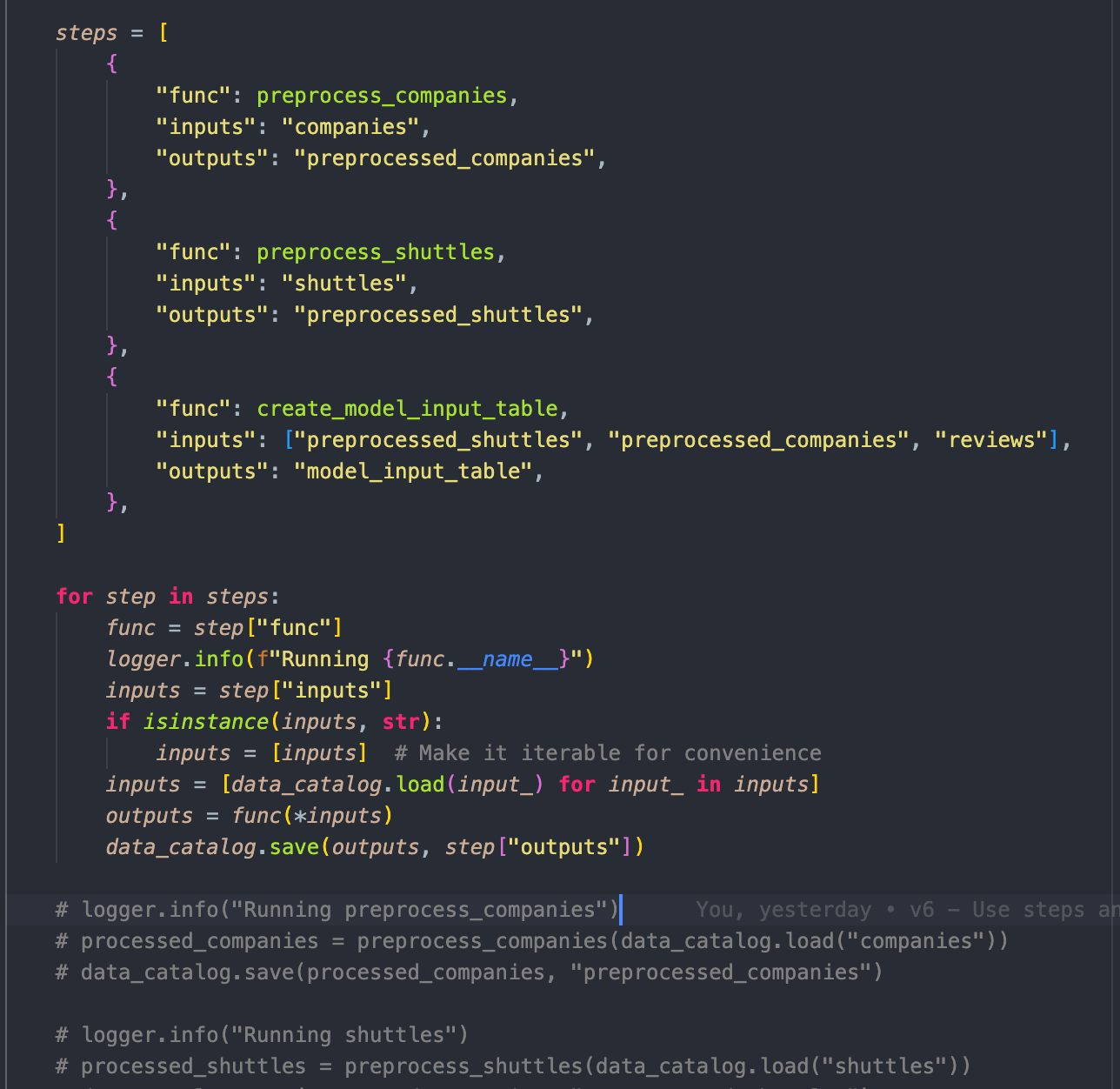
Step 7 - pipeline and node as a thin wrapper
## Step 8 - Replace functions with `node` and `pipeline`
## Step 9 - Extend Kedro with Hooks
Conclusion
We finish this with about 50 lines of code (ignore newline), and a library that looks very similar to Kedro. We have implemented a few components like: - ConfigLoader - DataCatalog - Hook - pipeline and node