LSTM
Reference: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
The diagrams are from Chris Colah’s blog.
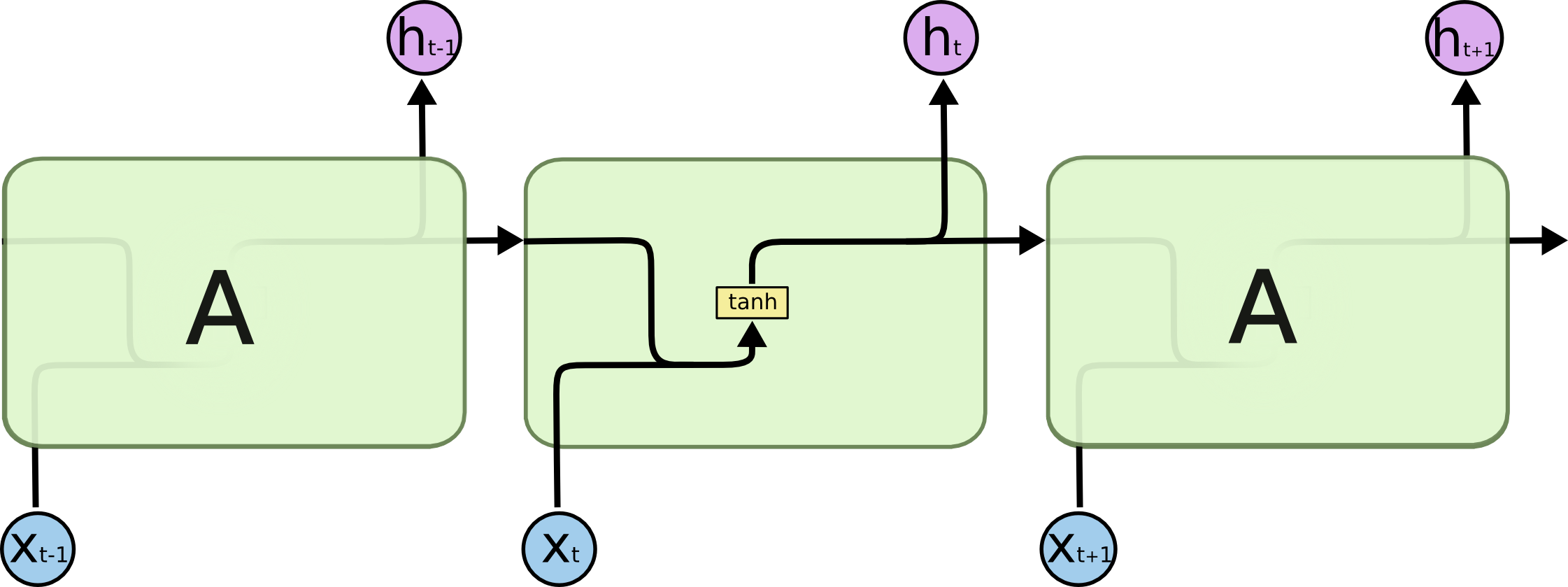
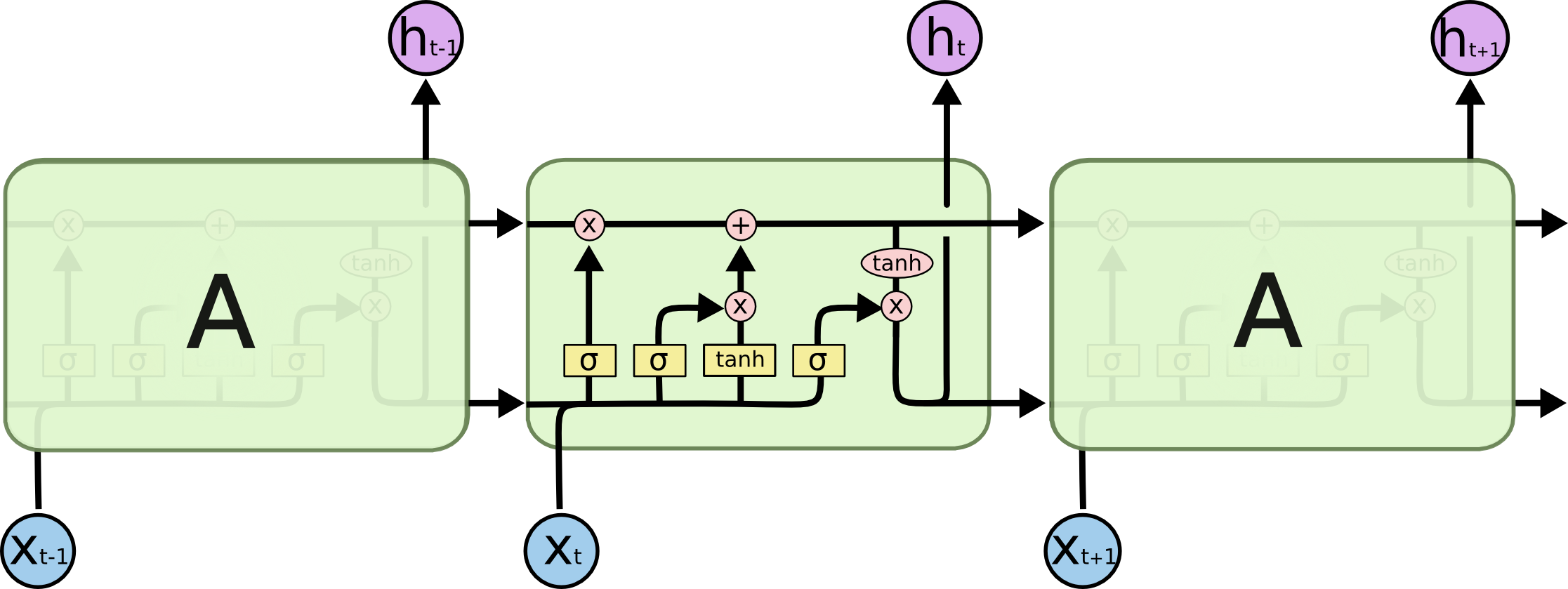
| RNN | LSTM |
|---|---|
 |
 |
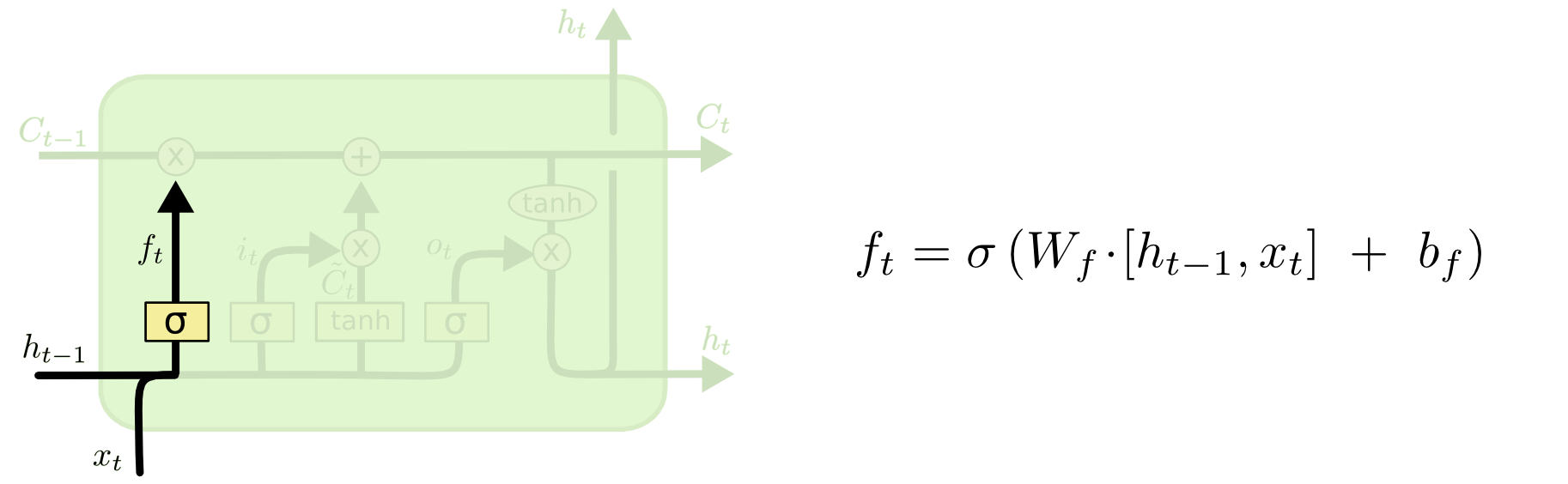 Forget Gate - Control the magnitude of cell state should be kept. Sigmoid range from (0 to 1). If 0, it means we should throw away the state cell, if 1 we keep everything.
Forget Gate - Control the magnitude of cell state should be kept. Sigmoid range from (0 to 1). If 0, it means we should throw away the state cell, if 1 we keep everything. 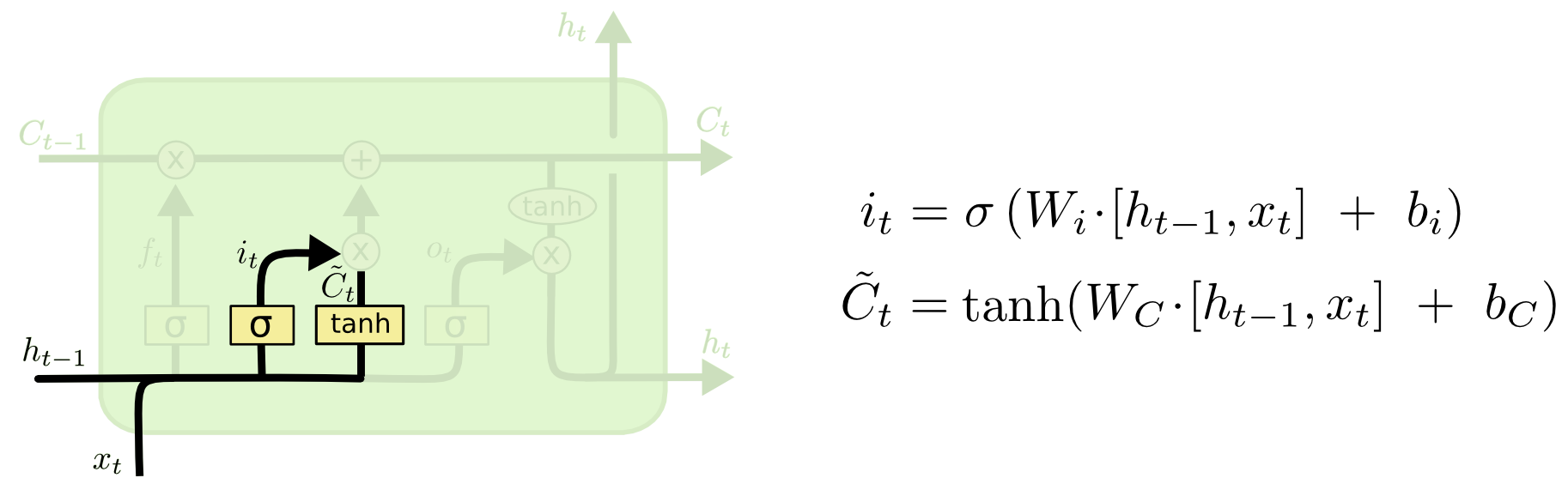 * Input Gate - Control what relevant information can be added from the current step. It takes hidden step from last step and the current input into consideration.
* Input Gate - Control what relevant information can be added from the current step. It takes hidden step from last step and the current input into consideration. 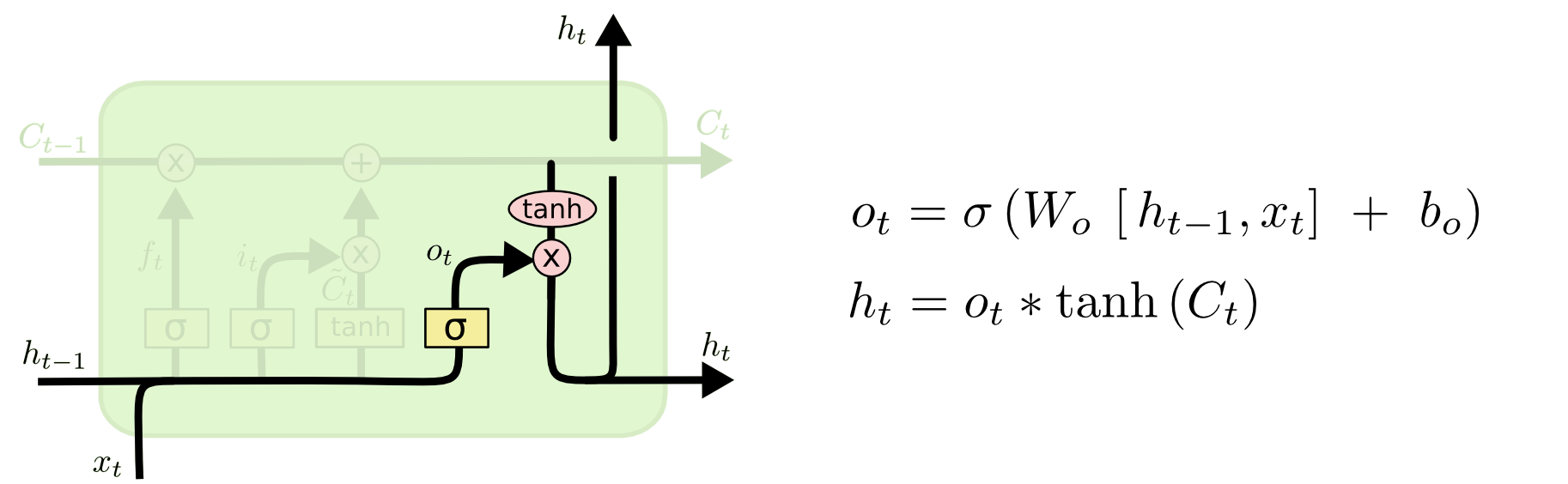 * Output Gate - finalize the next hidden state
* Output Gate - finalize the next hidden state
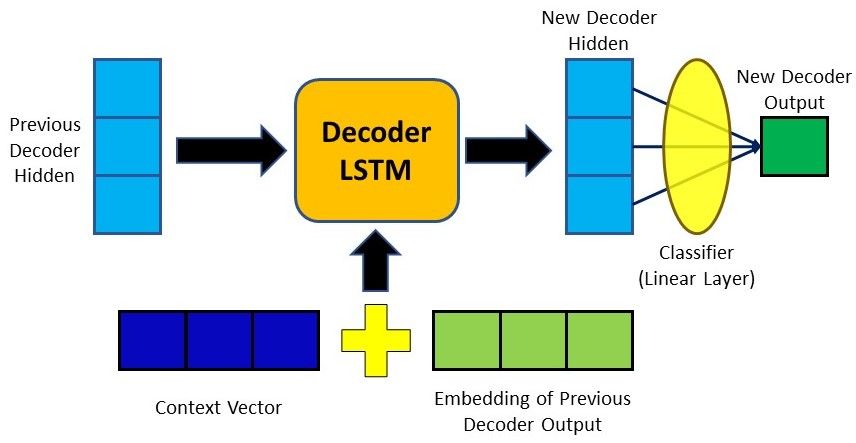
# Google Neurl Machine Translation (GNMT)
It more or less follow the attention mechanism described here.
https://blog.floydhub.com/attention-mechanism/#luong-att-step6
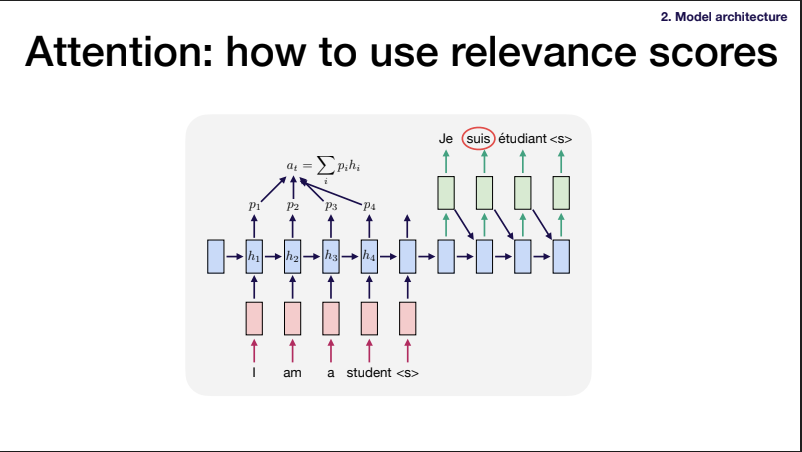
1.If you take the dot product of 1 encoder vector (at t_i) and decoder, you get a scalar. (Alignment Score) (1,h) * (h,1) -> (1,1) 2. If encoder have 5 time_step, repeat the above steps -> You get a vector with length of 5 (A vector of Alignment Scores) (5,h) (h,1) -> (5,1) 3. Take softmax of the alignments scores -> (attention weights which sum to 1) (5,1) 4. Take dot product of encoders state with attention weights (h, 5) (5, 1) -> (h, 1), where h stands for dimension of hidden state. The result is a “Context Vector”